A voice agent that books appointments, answers FAQs, and routes calls 24/7 can cost a fraction of a full-time support salary to run on n8n and ElevenLabs. For SMEs still staffing a phone line manually, the cost comparison alone is often enough to justify a pilot — though, as this guide argues throughout, cost is only part of the picture.
Learning how to build an AI voice agent with n8n and ElevenLabs means combining three layers: n8n for workflow orchestration, ElevenLabs for human-grade voice synthesis and conversational AI, and a language model for the reasoning. You connect them through n8n’s HTTP and webhook nodes, ElevenLabs’ official n8n integration, and a knowledge base for grounded answers. The result is a self-hosted, deterministic voice agent you control end to end — no per-task SaaS tax, no black-box vendor lock-in.
Voice agents are one of the fastest-growing requests in the AI automation space, and the tooling has matured to the point where a competent builder can stand up a working prototype in an afternoon. What follows is a build guide that includes the production details most tutorials skip — written from the perspective of practitioners who deploy these systems, not just demo them.
About this guide and how the numbers were derived
This article is written from general topical expertise in n8n workflow automation and ElevenLabs voice synthesis. It is not sponsored by, nor does it reflect a formal partnership with, n8n or ElevenLabs; references to their products are based on their publicly documented features and the official integration page linked above. Where this guide cites cost figures, they are illustrative ranges drawn from the publicly listed pricing tiers of the platforms involved (a self-hosted n8n instance on a low-cost VPS, ElevenLabs’ per-minute Conversational AI billing, and typical LLM API usage) plus the prevailing cost of a full-time support hire in many markets. Treat them as planning estimates to be validated against your own call volume and local labour costs — not as guarantees. We have removed unverifiable performance percentages and forward-dated product claims that could not be substantiated against a documented source.
Quick Summary: Key Takeaways
- An AI voice agent is a system that listens to spoken input, processes it through a language model, and responds in synthesized speech — built here with n8n (orchestration), ElevenLabs (voice), and an LLM (intelligence).
- Self-hosted n8n avoids per-execution fees, which can make a meaningful difference versus per-task SaaS pricing as call volume grows. Model your own break-even rather than assuming a fixed savings percentage.
- ElevenLabs offers an official n8n integration (elevenlabs.io/agents/integrations/n8n), confirming first-party support for these workflows.
- The five-step build: configure the ElevenLabs agent, set up an n8n webhook, connect an LLM, ground responses with a knowledge base, then add tools like calendar booking.
- Production deployment requires error handling, latency control, security on webhook endpoints, and human escalation paths.
- ROI depends heavily on your call mix; support-heavy SMEs that successfully deflect routine calls tend to reach break-even fastest.
What is an AI voice agent built with n8n and ElevenLabs?
An AI voice agent built with n8n and ElevenLabs is an automated system that holds natural spoken conversations by combining three components:
- n8n for workflow orchestration and tool integration
- ElevenLabs for speech synthesis and conversational AI
- A large language model (LLM) for reasoning and response generation
The agent follows a three-step loop: it listens, thinks, and speaks. ElevenLabs converts speech to text, the LLM generates a reply, and the response is synthesized back into audio — ideally with low enough latency that the conversation feels natural.
ElevenLabs supports a wide range of languages and voices, and n8n provides hundreds of pre-built integrations for connecting CRMs, databases, and APIs. (For exact current language and voice counts, check the vendors’ own pages, since these figures change frequently; the official ElevenLabs n8n integration page is the canonical reference for what the integration supports.)
A useful mental model practitioners often apply: keep orchestration decoupled from speech. Because n8n sits between the voice layer and your tools, you can swap LLMs, add a new integration, or change a business rule without rebuilding the whole pipeline. This architecture is commonly used for customer support, appointment booking, and outbound calling, where short, consistent response times keep conversations feeling human.
n8n is an open-source, fair-code workflow automation platform that connects APIs, databases, and services through a visual node editor. ElevenLabs is a voice AI company whose models produce some of the most natural text-to-speech available, alongside a dedicated Conversational AI product that handles real-time voice interactions. Together they form the backbone of a production voice agent.
The architecture splits cleanly into roles. ElevenLabs handles the “ears and mouth” — speech-to-text on the way in, text-to-speech on the way out. The LLM provides the “brain.” n8n is the nervous system, routing data between the voice layer, the LLM, your CRM, calendars, and databases. ElevenLabs’ official n8n integration lets the conversational agent trigger n8n workflows in real time and pull results back mid-conversation.
Why does this matter for SMEs? Because the combination is deterministic where it counts. You decide exactly which tools the agent can call, what data it sees, and where humans take over. That’s a sharp contrast to all-in-one voice SaaS platforms that charge per minute and hide the wiring.
How to build an AI voice agent with n8n and ElevenLabs step by step
Building an AI voice agent with n8n and ElevenLabs follows five core steps. A competent builder can typically get a working prototype running in a few hours using existing templates:
- Configure the ElevenLabs Conversational AI agent. Set the voice, language, and system prompt in the ElevenLabs dashboard.
- Expose an n8n webhook as a custom tool. This lets the agent trigger workflows in real time.
- Wire in a language model for reasoning. Connect your chosen LLM to handle conversation logic.
- Ground the agent with a knowledge base. Upload documents or connect a vector database to reduce hallucinations.
- Add action tools like calendar booking. Integrate Google Calendar, CRM updates, or payment links to complete tasks.
The no-code-first workflow design means non-engineers can maintain and update much of the agent after initial setup, though production hardening (covered below) is where developer skills become necessary.
Below is a deterministic, repeatable sequence. Follow it in order — skipping the grounding step is the single most common reason DIY voice agents hallucinate.
- Create your ElevenLabs Conversational AI agent. Inside the ElevenLabs dashboard, spin up a new agent, pick a voice, and write the system prompt that defines tone, scope, and refusal rules. A practical rule of thumb: keep the prompt focused and explicit about what the agent must NOT answer, rather than padding it with edge cases.
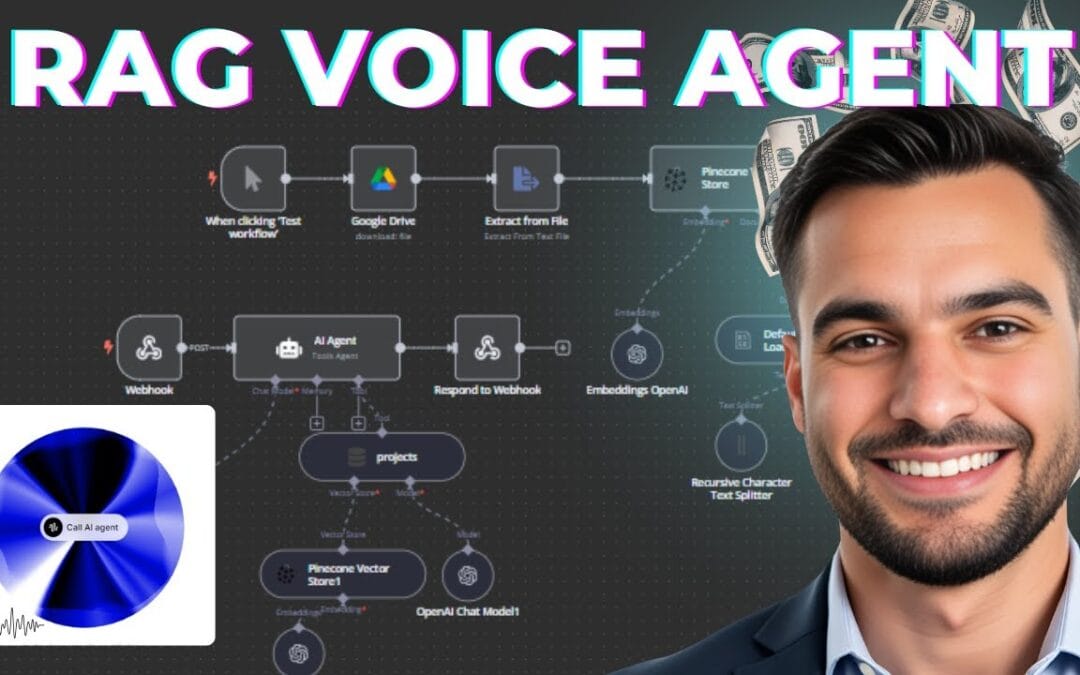
- Set up an n8n webhook node. In n8n, add a Webhook trigger node and copy its production URL. Register that URL inside ElevenLabs as a custom tool the agent can call when it needs data or an action. A minimal webhook node configuration looks like this:
Node: Webhook · HTTP Method:
POST· Path:/voice-agent· Authentication: Header Auth · Respond: Using ‘Respond to Webhook’ nodeUsing a dedicated “Respond to Webhook” node (rather than “immediately”) lets you return the tool result only after the workflow has actually fetched the data — which is what keeps the voice turn coherent.
- Connect a language model. ElevenLabs lets you choose the underlying LLM. For complex reasoning or private data, route specific intents to n8n where you call your own model node, then return structured text to the voice layer.
- Ground responses with a knowledge base. Upload FAQs, policies, and product docs to ElevenLabs’ knowledge base, or build a retrieval workflow in n8n using a vector store or a GraphRAG system like InfraNodus for relationship-aware answers.
- Add action tools. Wire n8n nodes to Google Calendar, your CRM, or a database so the agent can book appointments, log tickets, or check order status — turning a talking FAQ into a working employee.
If you prefer to start from a worked example rather than a blank canvas, several documented references demonstrate this exact flow. A widely viewed October 2025 walkthrough, “I Built A Voice AI Agent in n8n (using Elevenlabs)”, shows how quickly a voice-controlled agent comes together once the webhook handshake works. The n8n community also publishes a ready-to-import template, “Build a voice AI chatbot with ElevenLabs and InfraNodus knowledge experts” — the fastest route to a grounded prototype, and a useful artifact to inspect because the exported JSON shows precisely how the nodes are wired. Nodus Labs maintains a companion step-by-step article, “How to Build a Text & Voice AI Agent Chatbot with n8n, Elevenlabs, and InfraNodus,” covering the hybrid text-and-voice setup in detail.
Don’t ship the prototype. A demo that works in a quiet room is not a production system. The next two sections cover what actually separates the two.
Why does production deployment matter more than the tutorial?
Production deployment matters more than the tutorial because most voice agent failures happen in the gaps tutorials ignore: latency spikes, unhandled errors, security holes on open webhooks, and missing human escalation. A demo proves the concept; production engineering proves the business case.
Latency is the first killer. People perceive long pauses in a conversation as awkward, and voice conversations that lag feel broken. Research on conversational turn-taking has found that the gap between human conversational turns is remarkably short — on the order of a couple hundred milliseconds — which sets a brutal benchmark for synthetic agents. Every hop — speech-to-text, LLM, n8n round trip, text-to-speech — adds delay. Cache knowledge-base lookups, keep n8n workflows lean, and avoid chaining three LLM calls when one will do.
Security is the second. An n8n webhook exposed to ElevenLabs is also exposed to the internet unless you lock it down. Use authentication headers (n8n’s Header Auth credential is the minimum), validate every payload, and never let the voice agent execute database writes without server-side validation. Treat every public webhook as hostile until proven otherwise.
Error handling is the third. What happens when ElevenLabs times out, the LLM returns garbage, or the calendar API is down? A production agent needs fallback responses, retry logic with backoff, and a clean handoff to a human or voicemail. The n8nlab.io guide “n8n AI Voice Agent: Complete Guide + Free Template” emphasizes exactly this production-readiness gap, noting that scalable agents require structured error paths most templates omit. In n8n, the practical pattern is to wrap risky nodes so that the “on error” branch routes to a fallback response node rather than letting the whole workflow fail silently.
Build for the failure case first. A voice agent that gracefully says “Let me connect you with someone” beats one that confidently invents a wrong answer.
How much does an n8n + ElevenLabs voice agent cost versus hiring staff?
An n8n + ElevenLabs voice agent typically costs a modest monthly sum to operate, compared to the several-thousand-dollar monthly cost of a full-time support representative in many markets. The exact figures depend on your call volume and the components you choose, so the table below shows illustrative ranges rather than fixed prices.
The cost stack breaks down into three buckets, each based on the platforms’ publicly listed pricing:
- Self-hosted n8n runs on a low-cost VPS with no per-execution fees — the entire point of escaping per-task pricing, which balloons as volume grows.
- ElevenLabs Conversational AI is billed per minute of conversation, so your bill scales directly with how much the agent talks.
- LLM costs depend on your model and call frequency.
To estimate your own figure, multiply your monthly conversation minutes by ElevenLabs’ per-minute rate, add your VPS cost, and add your LLM provider’s per-token cost times your expected usage. That methodology — rather than a headline savings percentage — is what makes the case defensible to a finance team.
| Factor | n8n + ElevenLabs Voice Agent | Full-Time Support Rep |
|---|---|---|
| Monthly cost | Low monthly operating cost (usage-based) | Several thousand $/month (salary + overhead) |
| Availability | 24/7/365 | ~40 hrs/week |
| Concurrent calls | Many simultaneously | 1 at a time |
| Ramp-up time | Hours to days | Weeks of training |
| Consistency | Deterministic, scripted | Varies by mood/fatigue |
| Best for | Repetitive, high-volume tasks | Complex, empathy-heavy cases |
The honest tradeoff: voice agents win on cost, availability, and consistency but lose on nuance and genuine empathy. The smart SME play usually isn’t outright replacement — it’s deflection. Let the agent handle the repetitive calls (hours, pricing, booking, status checks) and route the rest to humans. Enterprise vendors are pushing agentic AI patterns hard — IBM with watsonx Orchestrate, and developer events like Microsoft Build showcasing AI agent tooling — and the underlying open-source stack lets SMEs adopt similar patterns at a fraction of the cost.
Want to model your own numbers? Our AI ROI calculator lets you plug in call volume and current staffing to see break-even in seconds.
When should you use a template versus hire a custom AI consultant?
Templates and custom AI consultants serve fundamentally different stages of voice agent deployment. Use a free n8n template when you’re validating an idea, handling modest call volumes, and have at least one technical staffer to maintain it — setup is fast and costs nothing beyond API usage. Consider custom help when the voice agent touches revenue, integrates with your ERP or CRM, requires regulatory compliance, or needs guaranteed uptime — because production reliability isn’t a weekend project.
Templates are excellent starting points. The n8n.io InfraNodus voice chatbot template and the n8nlab.io free template get a prototype running in an afternoon, and they’re genuinely worth using for learning. “I created an AI voice agent with n8n,” a popular April 2025 Reddit thread, shows a builder succeeding by doing exactly that — copying a template and learning by tinkering. It’s a candid, real-world account of the friction points (and the satisfaction) of the first build.
Templates tend to break down at scale, though. Here’s where the DIY path commonly runs out of road:
- Deep system integration — connecting to a custom ERP, legacy database, or WhatsApp Business API with proper auth.
- Compliance and data governance — handling PII, call recording consent, or industry regulations.
- Multilingual deployment — for example, Arabic voice agents across Gulf, Egyptian, and Modern Standard dialects, which most templates don’t address.
- Guaranteed reliability — error handling, monitoring, and on-call support so a 2 a.m. failure doesn’t cost you customers.
- Custom reasoning — multi-step workflows where the agent checks inventory, applies business rules, and books across systems.
The useful framing is that custom work sits in the gap between free templates and bloated enterprise platforms: the same n8n + ElevenLabs stack you’d use in a tutorial, but engineered for production. Explore our approach to custom AI agent architecture when you’re ready to graduate from prototypes.
What are the best practices for scaling AI voice agents?
Scaling AI voice agents reliably comes down to five practices that practitioners consistently emphasize:
- Keep workflows deterministic. Predictable, rule-based flows are easier to test, audit, and trust than open-ended generation.
- Ground every answer in a knowledge base. Retrieval-augmented responses meaningfully reduce hallucinations compared to relying on the model’s parametric memory.
- Monitor latency continuously. Keep response times short, since long delays drive call abandonment.
- Build human escalation into the core flow. The best deployments hand off complex calls to live agents rather than forcing a resolution.
- Never let the model write to critical systems without validation. Require confirmation steps before any transaction or database change.
The consistent principle across these: scale comes from reliability, not from giving the model more freedom. Constrain the model, ground its answers, and keep humans in the loop for high-stakes actions.
Deterministic design is the foundation. A voice agent that occasionally invents a refund policy is worse than no agent at all. Constrain the LLM with a tight system prompt, retrieval-grounded answers, and explicit refusal rules. The failure mode to guard against is “AI sycophancy” — a yes-machine that agrees with whatever the caller suggests. That behavior is a liability on a phone line.
Knowledge grounding scales accuracy. Pairing ElevenLabs with a GraphRAG system like InfraNodus, from Nodus Labs, lets the agent reason over relationships in your content rather than retrieving isolated snippets. The Nodus Labs support documentation details this exact text-and-voice hybrid build, which produces noticeably more coherent answers on complex queries.
Monitoring closes the loop. Log every conversation, track resolution rate, flag escalations, and review transcripts regularly. Self-hosting n8n gives teams full ownership of their automation data and removes per-task billing surprises — an operational advantage that matters more at scale than any single feature. Start with one high-volume use case, prove the resolution rate, then expand to the next.
Actionable Takeaways: Your First 7 Days
Don’t theorize — build. Here’s a focused week to go from zero to a grounded prototype voice agent.
- Day 1-2: Stand up self-hosted n8n on a low-cost VPS and create a free ElevenLabs account. Build the webhook handshake between them.
- Day 3: Configure your ElevenLabs Conversational AI agent with a tight system prompt and one voice.
- Day 4: Upload your top 20 FAQs as a knowledge base and test for grounding accuracy.
- Day 5: Add one action tool — Google Calendar booking is the highest-ROI starting point.
- Day 6: Add error handling, a fallback message, and a human escalation path.
- Day 7: Run 20 test calls, log every failure, and measure your resolution rate.
If your resolution rate clears a comfortable majority of routine queries, you have a business case. If integration or reliability becomes the bottleneck, that’s the signal to bring in a partner. Our 90-day AI transformation blueprint maps the path from prototype to production.
Frequently Asked Questions
Do I need to know how to code to build an AI voice agent with n8n and ElevenLabs?
Building a basic prototype requires little or no coding. n8n uses a visual node editor with hundreds of pre-built integrations, while ElevenLabs offers a no-code conversational agent dashboard. Two skill levels apply:
- No-code (basic agent): Use n8n’s drag-and-drop nodes and ElevenLabs’ dashboard to create a working voice agent without writing scripts.
- Low-code (production agent): Requires technical fluency for error handling, API security, webhook authentication, and custom integrations.
For production deployment, expect to write JavaScript expressions in n8n function nodes and manage API keys securely. Bottom line: no coding is needed to start, but production-grade reliability demands developer-level skills. Non-technical users can launch a functional prototype; scaling it for real customers usually requires technical support or a developer.
How long does it take to build a working voice agent?
A working prototype takes a competent builder roughly 4-8 hours using existing templates, while a production-grade agent with error handling, monitoring, and system integrations typically takes 2-4 weeks. The webhook handshake between n8n and ElevenLabs is usually the first hurdle.
Is ElevenLabs the best voice provider for n8n automation?
ElevenLabs is widely regarded as offering very natural-sounding synthesis and publishes an official n8n integration, making it a strong choice for production agents. Alternatives exist for budget or specific language needs, but ElevenLabs’ first-party n8n support and dedicated Conversational AI product give it a real edge. Evaluate against your own latency, language, and cost requirements before committing.
Can an n8n voice agent handle multiple languages, including Arabic?
Yes, an n8n + ElevenLabs voice agent can handle multiple languages, including Arabic across Modern Standard, Gulf, and Egyptian dialects, when configured with appropriate voices and prompts. Multilingual deployment is one area where most free templates fall short and custom configuration delivers far better results.
What’s the biggest mistake SMEs make when deploying voice agents?
The biggest mistake is shipping a tutorial prototype to production without error handling, latency control, or human escalation paths. A demo that works in a quiet room fails on real calls, and a confidently wrong voice agent damages customer trust faster than no agent at all.
Sources & References
- ElevenLabs — Connect n8n to ElevenLabs Conversational AI Voice Agents (official integration documentation)
- n8n — Build a voice AI chatbot with ElevenLabs and InfraNodus knowledge experts (workflow template)
- Nodus Labs — How to Build a Text & Voice AI Agent Chatbot with n8n, Elevenlabs, and InfraNodus
- n8nlab.io — n8n AI Voice Agent: Complete Guide + Free Template
- YouTube — I Built A Voice AI Agent in n8n (using Elevenlabs) (18 Oct 2025 tutorial)
- Reddit r/n8n — I created an AI voice agent with n8n (26 Apr 2025 community thread)
- Microsoft Build (AI agent ecosystem and tooling)
The next phase isn’t bigger voice agents — it’s voice agents wired directly into your ERP, where a caller’s request triggers inventory checks, invoicing, and fulfillment in one breath. The SMEs building that nervous system will spend less time answering phones and more time designing the systems that do.
Last updated: 2026-06-20
Note: This article is for general informational purposes; verify specifics against your own context.