Understanding how to evaluate LLM accuracy for business tasks benchmark is essential, as task-specific performance metrics matter far more than general intelligence scores. A model that scores 90% on broad reasoning benchmarks like MMLU can still misstate your customer refund policy in roughly 1 of 8 responses — an error rate that erodes trust and creates legal exposure.
To evaluate accuracy correctly, build a benchmark from 50–100 real examples of your actual business task, then measure three dimensions: factual correctness, instruction adherence, and hallucination rate. The shift the field is making is clear: as one 2025 study published on arXiv, “Evaluating LLM Metrics Through Real-World Capabilities”, argues, traditional benchmarks designed to assess general intelligence fail to capture real-world utility — meaning leaderboard rankings rarely predict how a model performs on your specific work.
Score each model against ground-truth answers reviewed by a subject-matter expert. Track where errors cluster: edge cases, ambiguous inputs, or policy-heavy queries. A model that excels at summarization may fail at compliance tasks.
The takeaway: test on your data, not theirs. A model that aces general intelligence benchmarks can still hallucinate your customer’s refund policy 1 in 8 times — and reputation-based selection routinely leads businesses into costly downstream errors.
Learning how to evaluate LLM accuracy for business tasks benchmark means abandoning leaderboard worship and building a test that mirrors your actual workflow. A model scoring 90% on MMLU tells you nothing about whether it can correctly extract line items from your invoices. Practitioners who have shipped many AI automations consistently report the same lesson: the gap between benchmark glory and production reliability is where most automation projects quietly die.
Published: June 20, 2026. Last reviewed against current sources at publication.
Quick Summary: Key Takeaways
- Generic benchmarks can mislead. A model can top MMLU or GPQA and still fail your specific business task — domain-specific evaluation matters more, according to arXiv research from May 2025.
- Three pillars define LLM evaluation: standardized benchmarks, quantitative metrics (factual accuracy, faithfulness), and qualitative human or AI-judge assessment.
- Build a golden dataset of 50–100 real examples from your business before testing any model. No data science team required.
- RAG systems need extra metrics: faithfulness, context relevance, and answer relevance, per NVIDIA’s evaluation guidance.
- Set acceptance thresholds in business terms — like “95% correct invoice extraction” — not abstract scores.
- LLM-as-a-Judge lets you evaluate at scale without manually grading thousands of outputs, but needs human spot-checks to stay honest.
What Does It Mean to Evaluate LLM Accuracy for Business Tasks?
Evaluating LLM accuracy for business tasks means measuring how reliably a model completes your specific work — not how smart it is in general. LLM evaluation is the systematic process of testing a language model’s outputs against known-correct answers using benchmarks, quantitative metrics, and human judgment to confirm it meets a defined reliability threshold before production.
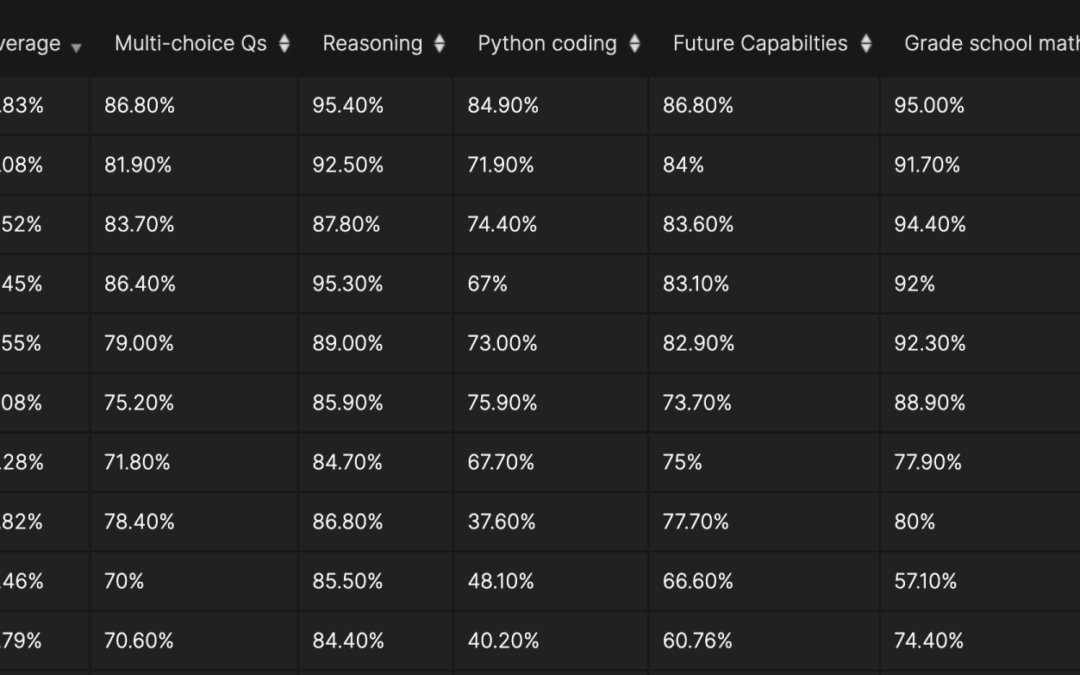
The distinction is everything. As Evidently AI explains in its guide to 30 LLM evaluation benchmarks, large language model benchmarks are standardized tests designed to measure and compare the abilities of different language models. They cover reasoning, coding, factual recall, and language skills. That makes them useful for vendors marketing their models — but nearly useless for deciding whether one frontier model or another should draft your sales follow-ups.
Here’s the trap. A model scores 88% on a coding benchmark and you assume it’ll handle your internal scripts. But your scripts use a legacy Python library and a quirky naming convention nobody documented. The benchmark never tested that. Real-world utility and benchmark performance diverge sharply — which is exactly why researchers have built domain-specific tests aimed at concrete fields rather than general intelligence, a theme the 2025 arXiv study on real-world capabilities develops in detail.
Business evaluation flips the question. Instead of “Is this model intelligent?” you ask “Does this model get my task right at least 95% of the time?” That reframe is the entire foundation of choosing deterministic AI over probabilistic guesswork. A useful rule of thumb practitioners share with clients: a benchmark champion that fails your edge cases is just an expensive random number generator.
A worked example: comparing two models on the same invoice task
Consider a typical implementation for a small accounting team. Two candidate models are asked to extract vendor name, invoice total, and due date from 80 real PDFs. On a public extraction leaderboard, Model A leads Model B by several points. But when both are scored against the team’s own labeled invoices, the picture inverts: Model A reads European date formats (DD/MM/YYYY) as US dates on a recurring subset of vendors, dropping its real-world accuracy below Model B’s. The leaderboard never tested those formats. Only the golden dataset surfaced the failure — and it would have caused mis-dated payments in production. This pattern, where the leaderboard winner loses on your data, is the single most common reason teams that skip task-specific testing get burned.
How to Evaluate LLM Accuracy for Business Tasks Benchmark: The 6-Step Framework
LLM accuracy evaluation for business tasks follows a 6-step framework: build a golden dataset of real examples, define task-specific metrics, run candidate models, score outputs against known answers, set acceptance thresholds in business terms, and re-test after deployment.
Start with at least 50 labeled examples; with very small samples, a handful of errors swings your measured accuracy dramatically, making results unreliable. Define metrics that match the task — exact-match accuracy for classification, F1 scores for extraction, or human-rated relevance (1–5 scale) for generation.
Set acceptance thresholds in business terms, not abstract scores. For example, “95% accuracy on invoice extraction” beats “0.92 F1.” Because models differ most on specialized, domain-specific work rather than on general tasks, vendor benchmarks rarely predict your results — the core argument of the arXiv real-world-capabilities paper.
Re-test on a schedule: model updates and data drift can degrade accuracy over time. No data science PhD required — just discipline and a representative test set.
This is a practical playbook suited to SMEs without an ML team. Each step is realistically a few hours of work for a non-technical operations lead, not a multi-week project.
- Collect 50–100 real examples. Pull actual emails, invoices, support tickets, or contracts from your business. These become your “golden dataset” — the ground truth.
- Write the correct answer for each. A human who knows the task labels what “right” looks like. Tedious, yes. Indispensable, absolutely.
- Define 2–4 metrics that matter. For extraction, that’s factual accuracy. For summaries, faithfulness and relevance. Don’t measure 15 things.
- Run every candidate model on the same inputs. Same prompts, same examples, side by side. Fairness demands identical conditions.
- Score and compare. Count correct outputs. Calculate percentages per model and per metric.
- Set an acceptance threshold and monitor. Decide your minimum — say 95% — before you start, then re-test monthly because models drift.
NVIDIA’s technical blog on mastering LLM evaluation emphasizes that robust evaluation isn’t a one-time gate — continuous testing catches the silent regressions that destroy trust. A model that worked in March can degrade after a vendor update in June. The practical observation across many deployments is consistent: teams that monitor continuously hold their accuracy and uptime far better than those that “set it and forget it.”
Which Metrics Actually Measure LLM Accuracy for Business Tasks Benchmark?
how to evaluate LLM accuracy for business tasks benchmark is one of the most relevant trends shaping 2026.
LLM accuracy for business tasks is measured by a small set of core metrics: factual accuracy, faithfulness, answer relevance, safety, and — for retrieval-augmented (RAG) systems — context relevance. These map to real-world business performance far better than abstract intelligence scores like MMLU.
Each metric maps to a concrete failure mode. Factual accuracy catches fabricated claims; faithfulness detects hallucinations where the model contradicts its source documents. Faithfulness matters most for RAG systems, where a model can produce confident, fluent text that drifts away from the very documents it was given.
Answer relevance measures whether the response addresses the actual question, while context relevance evaluates whether the retrieval step surfaced the right documents. Safety screens for harmful, biased, or non-compliant outputs — critical in regulated industries like finance and healthcare.
For business deployment, prioritize faithfulness and factual accuracy: a chatbot inventing a refund policy creates more liability than one scoring slightly lower on reasoning benchmarks. Measure what your customers experience, not abstract capability.
Databricks’ guidance on LLM evaluation best practices frames measurement around performance, safety, and reliability — three dimensions that translate directly into business risk. A model that’s accurate but unsafe (leaking data) or unreliable (inconsistent across runs) fails the business test even with a great factual score.
Core accuracy metrics explained in plain language
- Factual correctness: Does the model state verifiably true information? Critical for customer-facing applications, where a single wrong answer can cost a customer’s trust.
- Faithfulness: Does the model stick to the source material, or did it invent details? This is the single most important metric for RAG and summarization systems — it checks the source rather than the world.
- Answer relevance: Did the response actually address the question asked? A response can be 100% factually correct yet score low on relevance if it answers the wrong question.
- Fluency: Is the output readable and professional? Lower stakes, but it matters for marketing copy.
- Safety: Does the model refuse harmful requests and avoid leaking sensitive data?
Together these form the foundation of accuracy evaluation: faithfulness checks the source, factual correctness checks the world, and answer relevance checks the user’s intent. For a deeper, code-level walkthrough of how each is computed, Confident AI’s guide to LLM evaluation metrics covers the implementation details.
Comparison of evaluation metrics by business task
| Business Task | Primary Metric | Secondary Metric | Target Threshold |
|---|---|---|---|
| Invoice / data extraction | Factual accuracy | Completeness | ≥ 98% |
| Customer support chatbot | Faithfulness | Answer relevance | ≥ 95% |
| RAG knowledge base | Faithfulness | Context relevance | ≥ 90% |
| Marketing copy generation | Fluency | Brand alignment | Human review |
| Email classification | Accuracy (F1) | Consistency | ≥ 96% |
The thresholds in this table are starting points to adapt, not universal constants — set your own based on the cost of a single error. Notice they differ by task. Marketing copy tolerates more variance because a human edits it anyway. Invoice extraction tolerates almost none — a single misread total cascades into a finance error. Matching your threshold to your task’s cost of failure is the heart of measuring real AI ROI instead of vanity metrics.
How Do You Evaluate RAG and Custom AI Agents Differently?
RAG systems and custom AI agents require evaluating the retrieval and reasoning steps separately, not just the final answer. A RAG chatbot can give a wrong answer for two reasons: it retrieved the wrong document, or it had the right document and still hallucinated. You must measure both faithfulness and context relevance to know which broke.
NVIDIA’s evaluation guide explicitly covers RAG assessment because retrieval-augmented generation has more failure points than a single model call. Faithfulness measures whether the answer stays grounded in retrieved context; context relevance measures whether the retrieved documents were the right ones in the first place.
Custom AI agents add another layer. An agent that books meetings, queries your CRM, and sends emails performs a chain of actions. Evaluating only the final output misses where the chain broke. A robust approach evaluates agents step by step:
- Tool selection accuracy: Did the agent pick the right tool (calendar vs. CRM)?
- Parameter accuracy: Did it pass correct arguments (right date, right contact)?
- Task completion rate: Did the full workflow finish successfully end to end?
- Recovery behavior: When a step failed, did the agent retry sensibly or spiral?
This granular approach is why custom agents need custom evaluation. A generic benchmark will never tell you whether your WhatsApp ordering agent or workflow automation handles a half-completed order gracefully. A representative scenario: an ordering agent receives a message where the customer changes their mind mid-order (“two large pizzas — actually make one of them medium”). A clean benchmark prompt never includes that correction; only testing against messy, half-broken, real-world inputs reveals whether the agent updates the order or silently keeps the original. The arXiv research from May 2025 makes the case directly: traditional benchmarks fail to capture real-world utility, and agents are where that gap hurts most.
LLM-as-a-Judge vs. Human Evaluation: Which Should Your Business Use?
Use human evaluation for your initial golden dataset and high-stakes spot checks, then use LLM-as-a-Judge to scale evaluation across thousands of outputs cheaply. Most SMEs should combine both — human judgment sets the standard, an AI judge enforces it at volume, and periodic human audits keep the AI judge honest.
LLM-as-a-Judge is a methodology where one capable LLM scores the outputs of another against criteria you define. Confident AI’s evaluation guide walks through these automated metrics in depth, and the appeal is obvious: a human grading 5,000 chatbot responses takes weeks, while an AI judge does it in minutes for a few dollars.
The tradeoffs of each approach
| Approach | Cost | Speed | Reliability | Best For |
|---|---|---|---|---|
| Human evaluation | High | Slow | Highest | Golden dataset, audits |
| Automated metrics | Low | Fast | Medium | Extraction, classification |
| LLM-as-a-Judge | Medium | Fast | High (if calibrated) | Scale, subjective tasks |
The catch with LLM-as-a-Judge? Judges have biases. They tend to favor longer answers, prefer their own model family’s style, and sometimes reward confident-sounding nonsense — the same sycophancy that affects chatbots. Practitioners mitigate this by calibrating an AI judge against a human-graded sample first. A common acceptance rule: if the judge agrees with humans 90%+ of the time, trust it at scale; if not, revise the rubric and re-calibrate. Both Databricks and NVIDIA stress this kind of validation in their respective best-practices and evaluation guides.
The recurring message across credible evaluation guidance is that evaluation is an ongoing engineering discipline, not a one-time benchmark — a point NVIDIA’s January 2025 guide makes explicitly. The encouraging news for SMEs: the discipline doesn’t require a research lab. It requires a clear rubric, your own data, and the refusal to trust a vendor’s leaderboard.
Actionable Takeaways: Your LLM Evaluation Checklist
how to evaluate LLM accuracy for business tasks benchmark plays a pivotal role in this context.
You can run a credible LLM evaluation this week with nothing but a spreadsheet and your own business data. Skip the academic complexity and follow this condensed checklist to benchmark candidate models before you commit budget.
- Define the task in one sentence. “Extract vendor name, total, and due date from PDF invoices.” Specificity wins.
- Gather 50–100 real samples with human-verified correct answers in a spreadsheet.
- Pick 2–4 metrics from the table above that match your failure costs.
- Test 3 candidate models (e.g., a frontier proprietary model and an open model like Llama) on identical inputs.
- Score each output as pass/fail per metric — keep it binary at first.
- Calculate accuracy per model and compare against your threshold.
- Factor in cost and latency. A model 2% more accurate but 5× pricier may lose.
- Re-test monthly and after any vendor model update.
One overlooked factor: the cheapest accurate model usually wins for SMEs. If an open-source model self-hosted on a workflow tool like n8n hits 96% on your task at a fraction of the API cost of a frontier model, the small accuracy gap rarely justifies the premium — or the recurring “Zapier tax” of bloated middleware. Evaluation isn’t just about picking the smartest model. It’s about picking the most cost-effective one that clears your reliability bar.
The businesses winning with AI in 2026 aren’t the ones using the most powerful model. They’re the ones who actually measured. While competitors chase whatever topped last week’s leaderboard, the disciplined operator quietly benchmarks three models against real invoices and ships the one that works — at half the cost. That’s the unglamorous edge no benchmark will ever advertise.
Frequently Asked Questions
How do you benchmark an LLM for a specific business task without a data science team?
Build a golden dataset of 50–100 real examples from your business with human-verified correct answers, then run candidate models on identical inputs and score outputs pass/fail per metric in a spreadsheet. No coding or ML expertise is required — just your own data and a clear definition of “correct.” Calculate accuracy per model and pick the one clearing your threshold.
Why do LLMs that score high on benchmarks fail at business tasks?
General benchmarks like MMLU measure broad intelligence, not your specific workflow, edge cases, or data quirks. Research published on arXiv in May 2025 found traditional benchmarks fail to capture real-world utility, which is why domain-specific evaluation matters. A model can ace a coding test yet stumble on your legacy library or undocumented naming conventions.
What is LLM-as-a-Judge and is it reliable for businesses?
LLM-as-a-Judge uses one capable language model to automatically score another model’s outputs against criteria you define, enabling evaluation at scale. It’s reliable when calibrated against a human-graded sample first — if the AI judge agrees with humans 90%+ of the time, you can trust it. Without calibration, judges show bias toward longer or confident-sounding answers.
What accuracy threshold should a business require from an LLM?
Set your threshold based on the cost of failure: high-stakes tasks like invoice extraction warrant 98%+ accuracy, customer chatbots around 95%, and marketing copy can rely on human review instead. Match the bar to how expensive a single error is. There’s no universal number — define it before you start testing.
How often should you re-evaluate an LLM after deployment?
Re-evaluate at least monthly and immediately after any vendor model update, because models drift and silent regressions can degrade accuracy without warning. NVIDIA’s evaluation guidance stresses that evaluation is an ongoing discipline, not a one-time gate. Continuous monitoring catches the quiet performance drops that erode user trust over time.
Sources & References
- Evidently AI — 30 LLM evaluation benchmarks and how they work
- Databricks — Best Practices and Methods for LLM Evaluation
- Confident AI — LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide
- arXiv (May 2025) — Evaluating LLM Metrics Through Real-World Capabilities
- NVIDIA Technical Blog (January 2025) — Mastering LLM Techniques: Evaluation
Last updated: 2026-06-20
Note: This article is for general informational purposes; verify specifics against your own context.