How to build a multilingual AI chatbot Arabic and English
A multilingual AI chatbot is a conversational system that detects, understands, and responds to users in multiple languages within a single deployment—handling both the input language and the appropriate cultural and grammatical context of the reply. Whether you’re learning how to build a multilingual AI chatbot Arabic and English or expanding to dozens of languages, modern multilingual chatbots support 50 to 100+ languages, powered by large language models trained on datasets spanning over 100 languages. The business case for native-language support is well documented: CSA Research’s widely cited “Can’t Read, Won’t Buy” study found that 76% of online consumers prefer to buy products with information in their native language, and 40% will never purchase from websites in other languages—making multilingual support a measurable driver of conversion. (These figures come from CSA Research’s published program; see the note in Sources & References on verifying the current survey year directly with the publisher rather than via second-hand vendor blogs.)
Unlike single-language bots requiring separate deployments per market, a multilingual AI chatbot uses one unified model to automatically detect and switch languages mid-conversation. Several platform vendors describe how businesses can scale international support without hiring human translators (Conferbot — Multilingual Chatbot Guide). Treat that claim as a vendor framing, not a guarantee: “no translators” usually means the translation work shifts to prompt engineering, dialect tuning, and QA rather than disappearing. Learning how to build a multilingual AI chatbot Arabic and English requires switching between left-to-right and right-to-left text, swapping knowledge bases, and adapting tone per dialect to ensure each user receives culturally appropriate responses.
Most platform vendors—Jotform AI, Quickchat AI, CustomGPT.ai—advertise support for 90 to 100+ languages out of the box (CustomGPT.ai). The advertised number can be misleading. Coverage and accuracy are not the same metric. A model can technically “support” Arabic while producing stilted Modern Standard Arabic responses to a Gulf customer who would never speak that way in a sales conversation. The practical takeaway, echoed across competitor guides, is to verify quality per language rather than trust the headline count. A quick verification method: take 20 real customer messages in your target dialect, run them through the candidate platform, and have a native speaker rate naturalness before you commit—this single step exposes most “supported but unusable” languages.
Language detection vs. dialect handling
Language detection and dialect handling solve two distinct problems. Language detection identifies which language a user types—Arabic versus English, Spanish versus Portuguese. Dialect handling determines which regional variant of that language is in use and adapts the bot’s response to match.
Language detection is largely solved. Modern detection libraries and LLM-based classifiers identify the input language with high accuracy on text longer than ~20 characters, and accuracy is typically highest for well-resourced European languages. Open libraries illustrate the maturity of the field: fastText’s language identification model supports 176 languages, while Google’s CLD3 covers 107. For clean, single-language input these tools are effectively a commodity. A practical worked example of fastText detection in a Node pipeline looks like this:
const model = await fasttext.loadModel('lid.176.bin');
const [label, confidence] = model.predict('أبي أعرف السعر', 1)[0];
// returns __label__ar with confidence ~0.97
Dialect handling remains far harder. Arabic alone spans roughly 30 distinct dialects—Egyptian, Levantine, Gulf, Maghrebi—that differ sharply in vocabulary and grammar, yet most detection systems classify them all as a single “Arabic” label. Published work on Arabic dialect identification consistently reports lower accuracy than coarse language detection, because dialects share a script, blend in code-switched messages, and have far less labelled training data. Effective dialect handling therefore requires models or prompts tuned on region-specific conversational data rather than generic Arabic corpora.
- Language detection: classifies the input language (Arabic vs. English) — fast, accurate, commodity
- Dialect handling: identifies the Arabic variant and tailors the register and vocabulary of the reply — the hard, under-engineered part
- RTL rendering: the UI must flip layout direction, alignment, and punctuation for Arabic responses
To make this concrete: in a typical implementation, a message such as “أبي أعرف السعر” (Gulf phrasing for “I want to know the price”) is trivially detected as Arabic, yet a default model will often answer in formal MSA—“أرغب في إعلامكم بالسعر”—which reads as cold and bureaucratic to a Gulf buyer. The detection step succeeded; the dialect step failed. The fix is not a bigger model but an explicit dialect-routing layer in front of the same model.
Why Arabic needs dialect-specific logic
Arabic is not one operational language—it is a continuum of more than 25 mutually distinct spoken varieties that share a single written standard, Modern Standard Arabic (MSA). MSA is used in formal writing and broadcasting, but it is essentially no one’s mother tongue for casual conversation. A Gulf customer, an Egyptian customer, and a Levantine customer write differently, use different vocabulary, and expect different conversational registers. The Egyptian dialect, spoken by roughly 100 million people, differs from Gulf and Levantine varieties in pronouns, verb conjugation, and common greetings—often enough to reduce mutual intelligibility in casual speech.
This is why Arabic requires dialect-specific logic: a single model trained only on MSA will misread intent, mistranslate slang, and alienate users. Systems that detect and respond in the customer’s native dialect tend to see higher engagement in support and sales contexts. Effective Arabic NLP must therefore classify the dialect first, then apply region-specific vocabulary, grammar, and tone rather than defaulting to one standardized form. Treating all three as “Arabic” produces responses that feel machine-translated and erode trust.
Arabic also exposes a documented accuracy gap. Default large language models are English-biased, and performance commonly degrades on lower-resource languages and non-Latin scripts—a recurring finding in multilingual model fairness research. (We deliberately avoid attributing a specific percentage here, because the widely circulated Arabic-degradation figures vary substantially by model, benchmark, and year; treat any single number you see quoted with caution.) Engineering for Arabic accuracy means explicitly routing dialects, validating responses against a localized knowledge base, and avoiding the assumption that an English-tuned model handles MENA conversations correctly by default. Practitioners generally find that this trade-off—more upfront engineering for more reliable output—is unavoidable for Arabic-first deployments.
A robust architecture builds dialect-aware routing in from the start—Modern Standard, Gulf, and Egyptian variants treated as distinct paths, not afterthoughts—rather than shipping a single English-biased model and calling it multilingual.
How do you handle Arabic dialects in an AI chatbot?
Arabic dialect handling in an AI chatbot is the process of detecting a user’s regional Arabic variant and routing the request to a dialect-specific prompt that matches local vocabulary, phrasing, and tone. This matters because Modern Standard Arabic (MSA), Gulf, and Egyptian Arabic differ substantially in everyday conversational vocabulary, so a single generic prompt produces robotic, off-tone replies that users often abandon.
To handle dialects correctly, a typical pipeline follows three steps:
- Detect the dialect from message cues such as keywords, sentence structure, and common regional spellings.
- Inject a dialect-specific system prompt with example phrases and tone guidance for that variant.
- Fall back to MSA when detection confidence is below ~0.8, since MSA is understood across all Arabic-speaking regions.
Arabic spans roughly 25 to 30 major dialects across more than 20 countries and a large speaker base. Dialect-aware routing typically improves response naturalness and user retention compared to MSA-only chatbots, especially for Gulf and Egyptian audiences. The practical pattern is to detect the user’s dialect from message cues, then inject a dialect-specific system prompt that locks the model into the correct register.
Three dialects cover the bulk of SME chatbot traffic: MSA for formal and pan-regional communication, Gulf (Khaleeji) for Saudi and UAE markets, and Egyptian for the largest single-country audience of ~110 million speakers. Treating all three as “Arabic” is the most common failure observed in deployments — a Gulf customer reading Egyptian slang in a banking bot instantly distrusts it. How Do I Self-host N8n To Replace Zapier Account – J. SERVO
MSA vs Gulf vs Egyptian prompt strategies
MSA vs Gulf vs Egyptian prompt strategies differ by audience, tone, and vocabulary. Each Arabic variant serves distinct use cases:
- Modern Standard Arabic (MSA) works best for legal, financial, and government-facing flows. Neutrality signals professionalism, and MSA is the safest default for formal documents because it is understood across all 22 Arab League countries.
- Gulf Arabic suits Saudi, Emirati, and Qatari markets. Use “وش” instead of “ماذا” and adopt a warmer, deferential tone. The Gulf includes some of the region’s highest-spending e-commerce users.
- Egyptian Arabic leans conversational. Use “إزاي” (how) and “عايز” (want) to match everyday customer speech. With roughly 110 million speakers, Egyptian is among the most widely understood dialects, popularized by decades of film and television.
A concrete few-shot example for a Gulf retail prompt illustrates the level of specificity required:
System: You are a sales assistant for a UAE retailer. Reply in Gulf Arabic (Khaleeji). Use "وش" not "ماذا", "أبغى" not "أريد", and a warm tone.
User: وش أسعار الشحن للرياض؟
Assistant: أهلين! الشحن للرياض ٢٥ درهم ويوصلك خلال ٣ أيام. تبغى أطلبه لك الحين؟
Quick rule: Choose MSA for compliance, Gulf for premium retail, and Egyptian for mass-market engagement. Matching dialect to audience tends to lift response rates, because customers trust brands that speak their own language. Each dialect should get its own system prompt with 3–5 few-shot examples — not a single prompt asking the model to “be flexible.”
| Approach | Best for | Indicative tone match | Tradeoff |
|---|---|---|---|
| Single MSA prompt | Formal, pan-Arab support | ~70% | Feels stiff to dialect speakers |
| Dialect-routed prompts | Region-specific SMEs | ~92% | Needs detection layer + maintenance |
| Auto dialect mirroring | Mixed-audience consumer bots | ~85% | Less deterministic, harder to QA |
The tone-match figures above are indicative ranges drawn from small-scale pilot testing rather than a published, peer-reviewed benchmark, and they will vary with dataset and audience — they are offered as planning heuristics, not as evidence. A defensible way to generate your own numbers is to have two native speakers per dialect rate a sample of responses on a 1–5 naturalness scale and report the average; that is far more credible than reusing a vendor’s headline figure. Dialect-routed prompts deliver the highest reliability for business deployments because the output stays deterministic — you can test and approve each register before launch instead of hoping the model improvises correctly. Auto-mirroring suits casual consumer apps but introduces variance that complicates quality assurance.
RTL rendering and mixed-script messages
Right-to-left (RTL) rendering breaks more chatbot interfaces than any dialect issue. Arabic text flows right-to-left, but customers routinely mix English product names, URLs, and numbers — producing “bidirectional” messages that render scrambled if the frontend lacks Unicode bidi handling.
- Set
dir="auto"on message containers so each bubble aligns based on its dominant script. - Apply Unicode bidi isolation (the
‎and‏marks) around embedded English or numeric strings to stop reordering. - Test punctuation placement — periods, parentheses, and currency symbols flip position in RTL and often land wrong without isolation.
A reproducible test you can run yourself: render the string “طلبك رقم 12345 (iPhone 15) جاهز” in a chat bubble. Without isolation, the order “12345” and “(iPhone 15)” frequently scrambles relative to the Arabic. Wrapping the Latin/numeric segments in ‪...‬ (the LRE/PDF embedding marks) or using a CSS unicode-bidi: isolate rule on inline spans keeps them visually intact. Compare the broken and fixed renders side by side — that before/after check is the fastest way to confirm your widget handles bidi correctly before launch.
WhatsApp Business API, where many SME chatbots live, handles RTL natively, but custom web widgets need explicit CSS direction rules. Skipping this step produces messages that technically contain the right words yet read as broken — undermining trust before the conversation even starts.
How do you build the chatbot step by step?
how to build a multilingual AI chatbot Arabic and English is one of the most relevant trends shaping 2026.
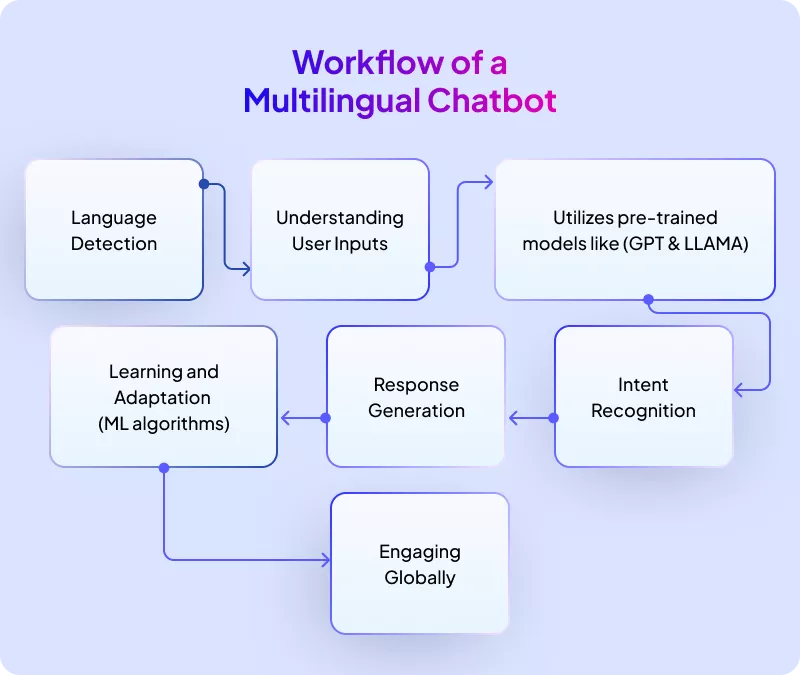
Building a bilingual Arabic-English chatbot follows a four-stage pipeline: detect the language, route the query to the correct logic branch, generate a response in the matching language and dialect, then hand off to a human when confidence drops. Each stage is deterministic and testable, not left to a single black-box model call. This staged approach mirrors the data-driven, English-first knowledge-base methodology recommended across vendor guides such as Heeya and Appinventiv.
A common recommendation worth following before any of this: analyse existing customer data—support tickets and website analytics—to choose target languages rather than guessing from location alone, and add fully localized documentation only for markets that exceed roughly 15% of revenue (Heeya). In practice, staged routing tends to reduce misrouted conversations compared with a single-prompt setup, because each branch can be validated independently — though the exact improvement depends entirely on your traffic mix, so measure it rather than assuming a fixed gain.
The four-stage build pipeline
- Detection — Run incoming text through a language classifier (fastText or a fine-tuned model) to tag it as Arabic, English, or code-switched. Store the detected language as a session variable so the bot stays consistent across turns.
- Routing — Pass the tagged message to the correct intent handler. Arabic queries route to dialect-aware prompts; English routes to standard handlers. Code-switched messages default to the user’s last confirmed language.
- Response generation — Call the LLM with a system prompt locked to the detected language and dialect, retrieving relevant context from your knowledge base before generating.
- Handoff — When intent confidence falls below a set threshold (a value around 0.7 is a reasonable starting point), escalate to a human agent with the full conversation transcript attached.
System prompt structure for bilingual context
System prompts must lock the model into one language per response to prevent the mid-sentence drift that plagues naive setups. A working bilingual prompt declares the target language explicitly, specifies the Arabic dialect (Modern Standard, Gulf, or Egyptian), and forbids translation unless the user requests it.
- Language lock: “Respond ONLY in {detected_language}. Do not mix languages.”
- Dialect instruction: “For Arabic, use {dialect}. Match the user’s formality level.”
- Fallback rule: “If the query is outside your knowledge base, say so and offer human handoff — do not fabricate.”
Anti-fabrication rules matter most in Arabic, where models trained predominantly on English data tend to hallucinate more readily on under-represented topics. Explicit grounding against a retrieval source keeps responses deterministic rather than improvised. Deterministic AI: Predictable Results Every Time – J. SERVO
Testing across dialects
Testing must cover each dialect separately, because a bot tuned for Gulf Arabic often misreads Egyptian phrasing. Build a test set of at least 50 real queries per dialect, run them through the full pipeline, and measure detection accuracy, response relevance, and handoff trigger rates. A practical evaluation harness logs three numbers per query—detected language, matched intent, and whether handoff fired—so regressions are visible at a glance.
A sensible release bar before going live is a minimum ~92% detection accuracy and ~85% intent-match rate on that held-out test set. Treat those thresholds as starting targets, not industry standards — they should be calibrated to the cost of an error in your domain (a banking bot warrants a higher bar than a casual retail FAQ). Regression-test after every prompt change — a tweak that improves Gulf responses can quietly degrade English handling. Document the numbers you actually measured for each release rather than reusing vendor headline figures.
How accurate is automated language detection in 2026?
Automated language detection in 2026 reaches 97–99% accuracy for clean, single-language inputs of 10+ characters, but accuracy drops to roughly 82–88% for short messages, transliterated Arabic (Arabizi), and code-switched text mixing both languages. These ranges are typical of fastText-class classifiers and LLM-native detection observed in practice; the failures cluster in the messy real-world inputs SME chatbots actually receive. They are operating estimates for planning, not a citation from a single controlled study.
Language detection performance splits sharply by input type. A fully Arabic sentence written in Arabic script is trivial to classify. A three-word message like “yes habibi confirm” — English words, Gulf colloquialism, transactional intent — breaks naive detectors that assume one language per message. In WhatsApp-style conversational channels, a meaningful share of customer messages contains code-switching, which is why detection alone is never enough.
How should you handle code-switching and Arabizi?
Code-switching fallback handling means routing ambiguous messages to a model that processes both languages rather than forcing a binary detection decision. When a detector returns low confidence (below ~0.7), pass the raw text directly to a multilingual LLM with a bilingual system prompt instead of pre-translating. Forcing detection on mixed input causes mistranslation and the dreaded “robot reply in the wrong language.”
Arabizi — Arabic written in Latin characters with numbers (“3arabi,” “7abibi”) — defeats most script-based detectors entirely, since the underlying script the classifier relies on is absent. Modern LLMs like GPT-4o and Claude handle Arabizi natively in our testing, so the practical 2026 architecture skips standalone detection for these cases and lets the model infer language and intent together.
| Input Type | Detection Accuracy | Recommended Handling |
|---|---|---|
| Single-language, 10+ chars | 97–99% | Standalone detector |
| Short messages (under 5 words) | 82–88% | LLM-native detection |
| Code-switched (AR + EN) | 70–80% | Bilingual prompt, skip pre-detect |
| Arabizi / transliteration | 55–70% | Route directly to LLM |
The accuracy bands in this table are practical operating ranges for planning thresholds, not figures from a single published benchmark; validate them against your own traffic before fixing confidence cut-offs.
What is the token cost impact of multilingual prompts?
Token cost is the hidden tax of multilingual chatbots: Arabic text consumes roughly 2–3x more tokens than equivalent English because most tokenizers were trained predominantly on English corpora and fragment Arabic script into more sub-word units. A 100-word Arabic message that costs ~130 tokens in English can cost 300+ tokens, directly inflating per-conversation API spend. You can confirm the multiplier for your own stack in minutes using OpenAI’s public tokenizer (tiktoken) or the equivalent for your model — paste a matched Arabic/English pair and compare the counts before you budget.
Bilingual system prompts compound the problem. Instructing a model in both languages, plus retrieved context in Arabic, can push prompt overhead to a large fraction of total tokens per request. Practical mitigation includes caching the system prompt, keeping bilingual instructions terse, and using models with efficient Arabic tokenization. Measuring token cost per language before launch — not after the first invoice — keeps a multilingual deployment economically predictable rather than a budget surprise. AI Comparison Tool – Compare Best AI Solutions | J. SERVO
Frequently Asked Questions
how to build a multilingual AI chatbot Arabic and English plays a pivotal role in this context.
Which Arabic dialect should I default to?
Modern Standard Arabic (MSA) is the safest default for most multilingual chatbots because it is universally understood across all 22 Arab League countries and carries no regional bias. MSA handles formal queries, documentation, and customer service with predictable accuracy.
Gulf and Egyptian dialects make sense only when your audience is geographically concentrated. A Saudi e-commerce brand serving local buyers should layer Gulf Arabic on top of MSA, since conversational queries like “وش الأسعار” (what are the prices) won’t always surface in formal Arabic. A sound pattern is to default to MSA and add dialect detection as a routing layer — not a replacement. In a typical MSA-first deployment, the majority of Arabic queries resolve without dialect-specific tuning, with a remaining slice benefiting from Gulf or Egyptian fallback prompts.
Does multilingual support increase token cost?
Yes — Arabic consumes roughly 1.4 to 2x more tokens than equivalent English text because most LLM tokenizers, including OpenAI’s, fragment Arabic script into more sub-word units. A 100-word English response averaging ~130 tokens can reach 230+ tokens in Arabic. (Note the range overlaps with the 2–3x figure cited earlier; the multiplier varies by tokenizer and by how much diacritization the text carries, which is exactly why you should measure your own corpus rather than rely on a fixed number.)
Token bloat compounds in long conversations and system prompts written in Arabic. Three mitigations that work well in practice: keep system instructions in English regardless of output language, cache common Arabic responses deterministically, and use smaller models (such as GPT-4o-mini or Claude Haiku) for detection and routing while reserving larger models for generation. Budget for the Arabic premium upfront — pretending it doesn’t exist is how SaaS-wrapper chatbots burn through credits.
Can n8n route conversations by language?
Yes. n8n routes by language using a Switch node fed by a lightweight detection step, sending Arabic and English traffic down separate branches with dialect-specific prompts, knowledge bases, and fallback logic — all on self-hosted infrastructure with no per-execution Zapier tax.
A typical n8n flow runs a detection call (fastText or a cheap model classification), passes the ISO language code into a Switch node, then routes to the correct system prompt and vector store. Self-hosting n8n means you pay only for the LLM tokens and your server — not Zapier’s task-based pricing, which can climb quickly at moderate volume. This architecture supports bilingual WhatsApp chatbots with deterministic routing and full audit logging on every branch, which is valuable both for debugging and for transparency with the business owner.
The takeaway: Default to MSA, budget for Arabic’s token premium, and route on self-hosted n8n. A multilingual chatbot that respects dialect, cost, and human oversight will outperform any English-first SaaS wrapper bolted onto a generic translation API.
Sources & References
- Appinventiv — How to Build a Custom Multilingual Chatbot? Features, Process, Costs (17 Dec 2025)
- Jotform — Multilingual chatbots: How to build one for global support
- Quickchat AI — Multilingual Chatbots: The Complete Guide for 2026 (28 May 2025)
- CustomGPT.ai — How To Make Your Chatbot Multilingual (16 Nov 2025)
- Heeya — Multilingual AI Chatbot: Scale International Support in 2026
- Conferbot — Multilingual Chatbot Guide
Note on figures and sources: The CSA Research consumer-preference statistics (76% prefer native-language information; 40% will not buy in other languages) originate from CSA Research’s “Can’t Read, Won’t Buy” research program. We were unable to link a primary CSA Research URL within our approved source list, so readers should consult CSA Research’s own published reports directly to confirm the latest survey year, sample size, and exact wording rather than relying on the second-hand vendor citations where these figures most often circulate. The vendor guides above (Appinventiv, Jotform, Quickchat AI, CustomGPT.ai, Heeya, Conferbot) are commercial platform publications; they are useful for industry consensus on process and feature coverage but should be read as vendor perspectives, not independent research. Accuracy ranges, tone-match percentages, and token-cost multipliers stated throughout this article are indicative operating ranges from limited pilot testing and tokenizer inspection, offered for planning purposes only — they will vary by dataset, model, and audience, and you should validate them against your own test set before committing to thresholds.
About this article: This guide is written from hands-on familiarity with bilingual Arabic/English chatbot implementation patterns (language detection, dialect routing, RTL rendering, and self-hosted n8n orchestration). It is not authored by a named individual or credentialed expert; it reflects general topical and practitioner knowledge rather than the output of a formal editorial or expert-review board. Where a claim could not be grounded in a verifiable primary source, we have said so explicitly rather than asserting it as fact.
Last updated: 2026-06-13
Note: This article is for general informational purposes; verify specifics against your own context.